参考教材《TCP/IP详解 卷2:实现》,文内示意图大多取自该教材。本文为复习时自行总结,难免存在不全或者错误,求求大伙轻喷。如有问题可以留言在文末评论区,或者直接私聊,我会及时更改文章内容。
第一章 概述
基本框架
网络输入输出层间框架
基本框架如下图所示,我们会在后面详细讨论输入输出
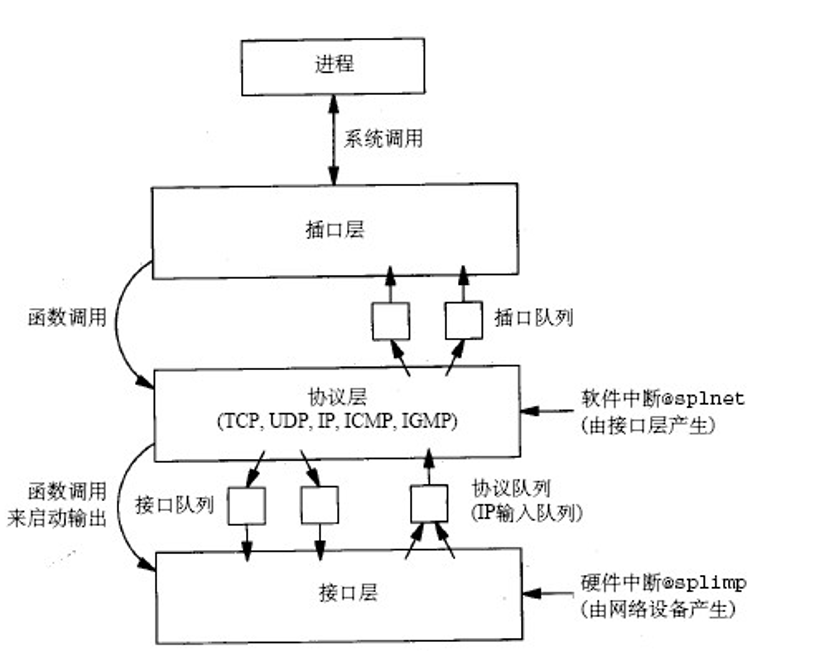
UDP示例socket程序框架
这段C代码也充当后续我们分析输入输出时的例子
1 | /* |
输出流程
下面考虑插口层调用sendto()函数时发生的流程
mbuf结构
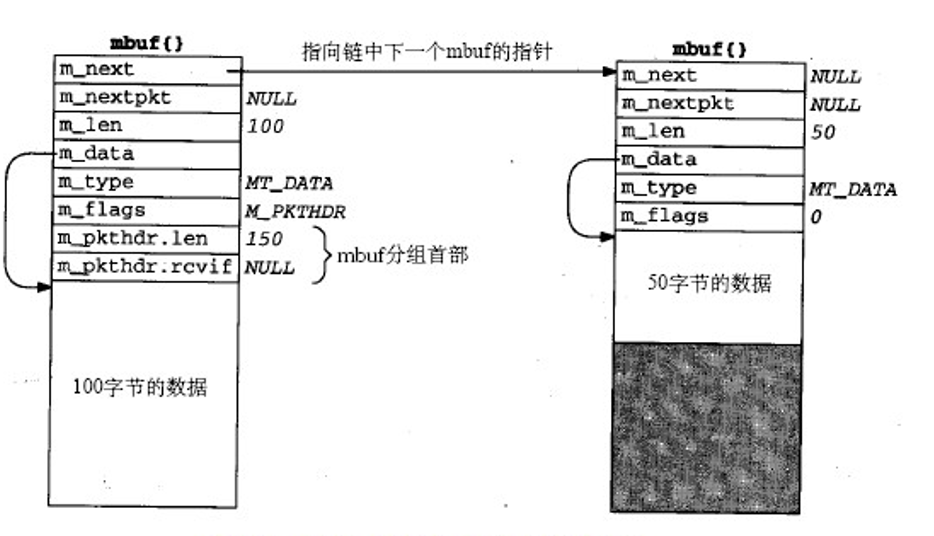
如图是一个含有150字节的mbuf分组。宏观来看,可以发现mbuf是由m_next指针链接的单链表,这种安排方式叫做mbuf链表.
细节来看各个成员变量及其含义:
m_next用来连接下一个mbufm_nextpkt用来连接下一个mbuf分组m_len标识所在的mbuf包含的data数据长度m_type标识所在mbuf的类型m_data指向所在mbuf的数据开头地址m_flags用来标识所在mbuf的类型,但不同于m_type
以及两个特殊的成员,共同组成了mbuf分组首部,占8个byte。只有当mbuf的flags为M_PKTHDR时,才启用:
m_pkthdr.len用来表示整个分组的data长度m_pkthdr.rcvif
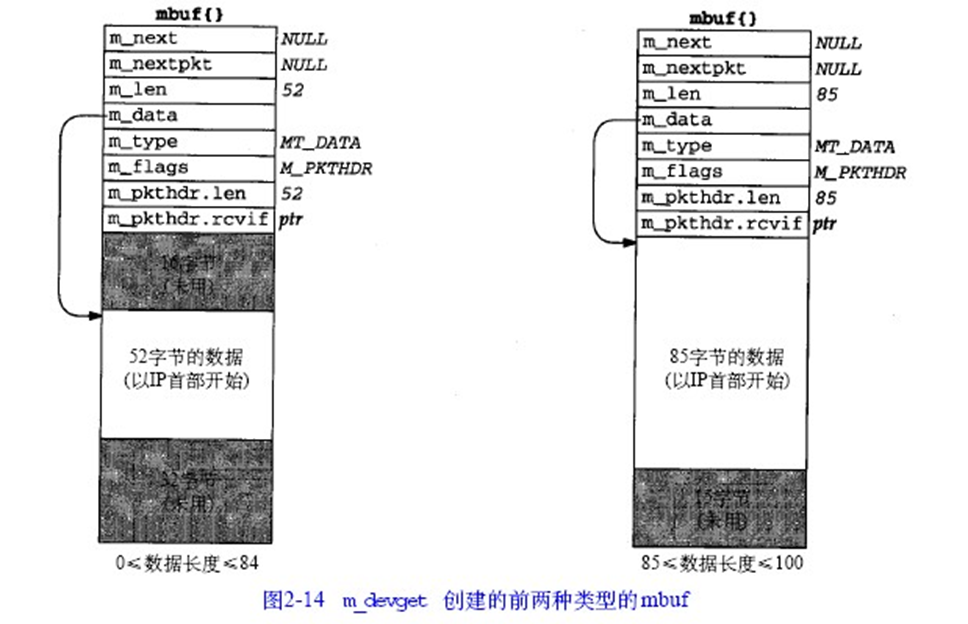
整个mbuf的size为128 byte,除去前面的成员变量和首部的话可以存储100字节的数据,如果不包含mbuf分组首部,则可以存储108字节。
添加IP和UDP首部
下图是以一个150字节数据的mbuf,加入IP和UDP首部后的mbuf情况
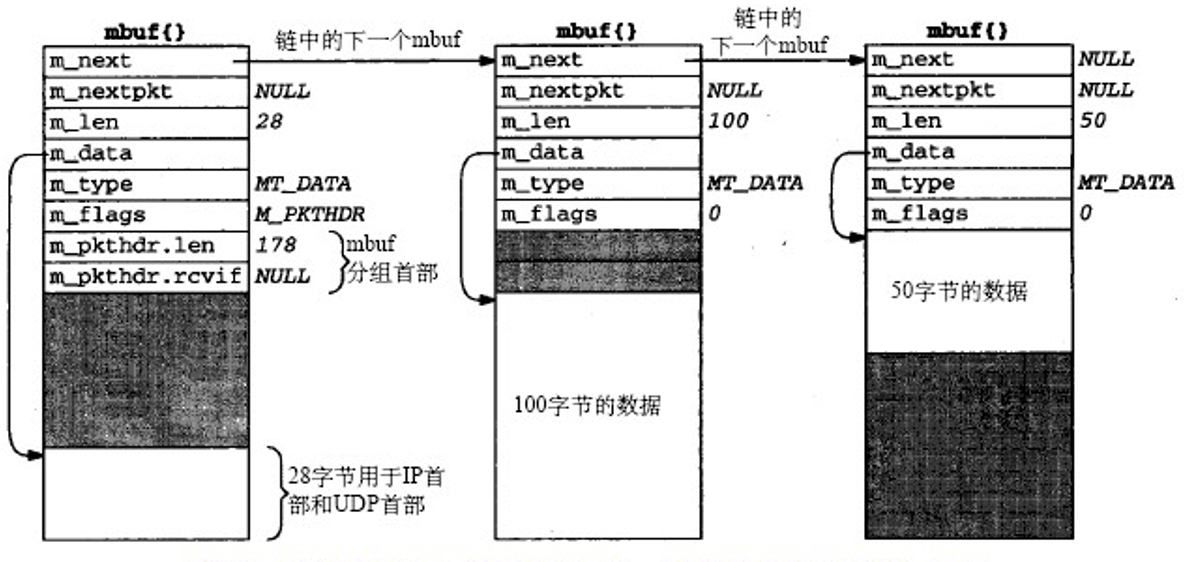
具体来说,当UDP输出例程被调用时:
- 首先讲原有指向150byte的mbuf链表的指针作为参数进行传递
- 然后新建一个含有28字节IP首部和UDP首部的mbuf
- 将新建的mbuf的
m_next域指向原有传入的mbuf指针 - 将原有8byte的分组首部copy到新的首部
另外需要注意,我们在第4步中将分组首部复制到了新的mbuf中,那么新旧mbuf的m_flags域也要进行相应的设置。
于是新的mbuf成为了新的分组首部,且mbuf链表的总长度由2变3,mbuf分组的数据长度增加了28,变成了178byte。可以看到,在分组首部和IP/UDP首部之间存在78字节的空缺,通过适当的调整m_data和m_len我们可以在其中加入之后的首部,而不需要新建mbuf.
之后由UDP例程填写UDP首部和IP首部的一部分内容,且UDP检验和计算后也会存储在这里。接着,UDP输出例程调用IP输出例程,并把此mbuf链表的指针传递给IP输出例程。UDP和IP首部剩余的部分由IP输出例程进行填写,如IP校验和等等。
以太网输出
在完成上述操作后,IP输出例程调用以太网接口并把mbuf链表继续传递,以太网输出函数流程如下:
- 将32为IP地址解析为48位6个字节的以太网地址
- 向mbuf首部之前空出来的地方,添加14字节的以太网首部
- 将mbuf放入以太网输入输出队列队尾
14字节的以太网首部包含:6字节的以太网源地址,6字节的以太网目标地址,2字节的以太网帧类型
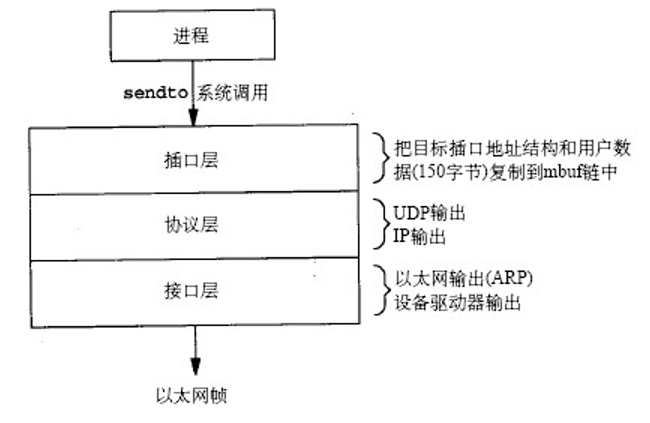
小结
如下图所示,当进程调用sendto()系统调用时:
- 将用户数据拷入mbuf链表
- 添加UDP/IP首部
- 添加以太网首部,随后输出
输入处理
输入处理与刚谈到的输出处理不同,因为输入时异步的。具体来讲,他是通过一个输入完成的中断使以太网设备驱动程序来接受一个输入分组,而不是通过进程的系统调用。内核处理这个设备中断,并调度设备驱动程序进入运行状态。
以太网输入
假设一个正常的接受已经完成,以太网设备驱动程序会处理这个中断。在下图的这个例子中,我们接收了54个字节的数据,并将其复制到了mbuf当中,其中包括:20字节的IP首部,8字节的UDP首部,26字节的数据
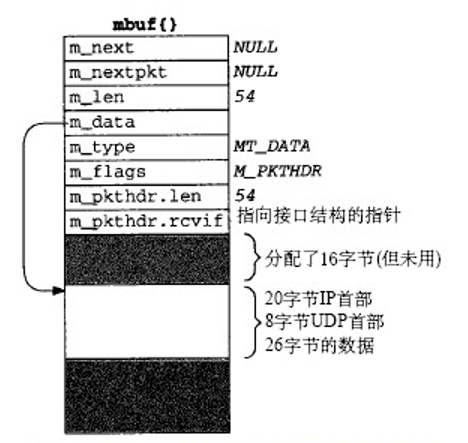
可以看到其中分配了16字节,但是并没有使用。这个空间是分配给接口层的首部,其他数据存放在剩余的84字节中。
接着设备驱动程序会根据以太网帧中的类型字段来决定这个分由那个协议层来接收。在这个例子中,将由IP输入例程进行接收。从而mbuf会被加入到IP输入队列当中,另外会产生一个软中断来执行IP输入例程。
IP输入
IP输入是异步的,通过软中断来执行。这个软中断由接口层接收到IP数据报时触发。IP处理例程会循环处理IP输入队列上的每一个数据报,并在整个队列完成后返回。IP数据报处理流程包括:
- 验证IP首部校验和
- 处理IP选项
- 验证数据报 被传递到正确的主机(通过比较目的IP地址和主机IP地址)
- 转发数据包(当系统为路由器且目的地址为其他IP时)
- 如果到达最终目的地址,则会调用下一步输入例程(如TCP、UDP、ICMP及IGMP等)
在本例中,我们假设下一步输入处理例程为UDP
UDP输入
UDP输入例程会验证UDP首部中的各字段,然后确定是否一个进程接收次数据报。
一个进程可以接收到指定UDP端口的所有数据报,或让内核根据源与目标IP地址与目标端口号来限制数据报的接收。
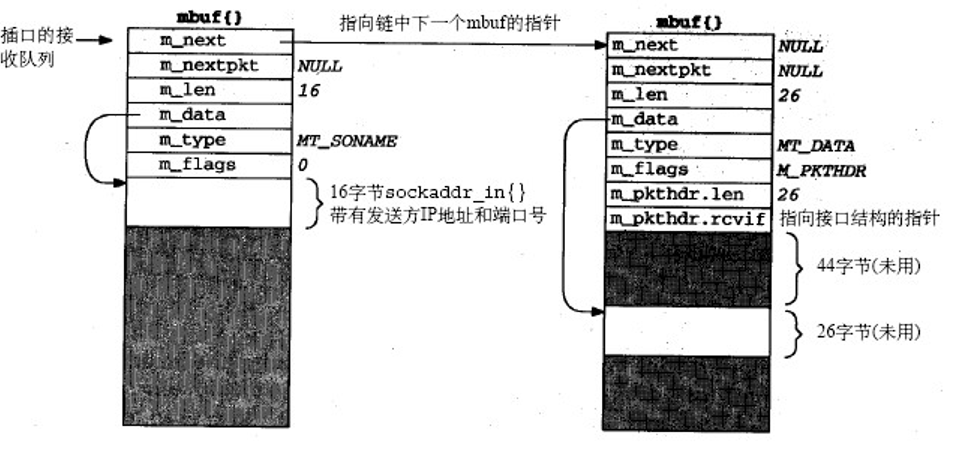
可以看到,原有的mbuf被插入到了一个新的mbuf中。由于我们的数据报需要传给进程,所以这个新的mbuf包含了发送方的IP地址和端口号(从IP首部中拆分出来)。
另外,如果我们对比图中右侧放置数据的mbuf和以太网输入的mbuf可以发现,m_len和m_pkthdr.len 都减小了28字节(即IP首部和UDP首部的部分),m_data指向的地址也减小了28,只保留了26字节的data数据。
链表的第一个mbuf的m_type类型被设置为了MT_SONAME,且这个mbuf是由插口层建立,将这些信息返回给调用系统调用recvfrom和recvmsg的进程中。即便第二个mbuf有空间可以用来存储插口地址结构(发送方IP地址和端口号),也不能放置在一起。因为两个mbuf的类型并不相同,一个是MT_SONAME,一个是MT_DATA。
进程输入
当进程调用recvfrom()时,进程会在内核中保持睡眠状态。现在,内核会唤醒我们的进程,并把mbuf中的数据复制到程序的缓存中。然后释放掉这些mbuf
在调用recvfrom时,我们将第5、6个参数设置为NULL,表示我们并不关心发送方的IP地址和UDP端口号,此时recvform只会返回第二个mbuf的data。
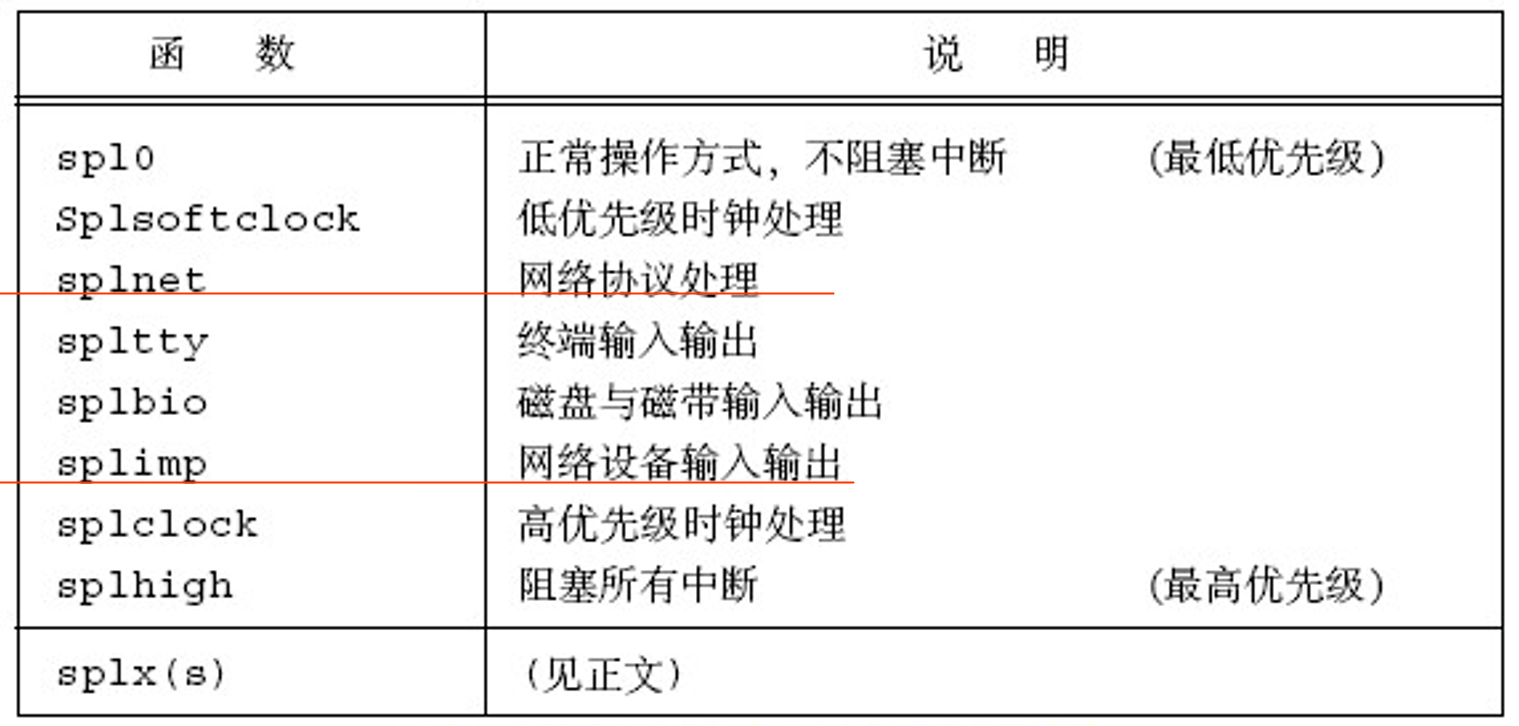
中断级别
如下图所示是8个硬件及软件中断的优先级。划红线的部分为我们之前谈到的两个部分:splnet(软中断,执行协议层代码),splimp(硬中断执行接口层代码)
第二章 存储器存储
mbuf分类
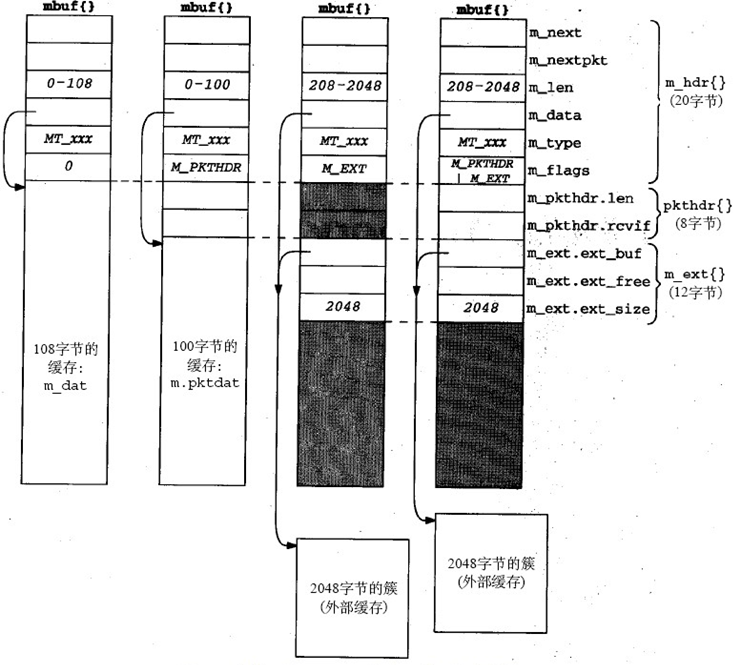
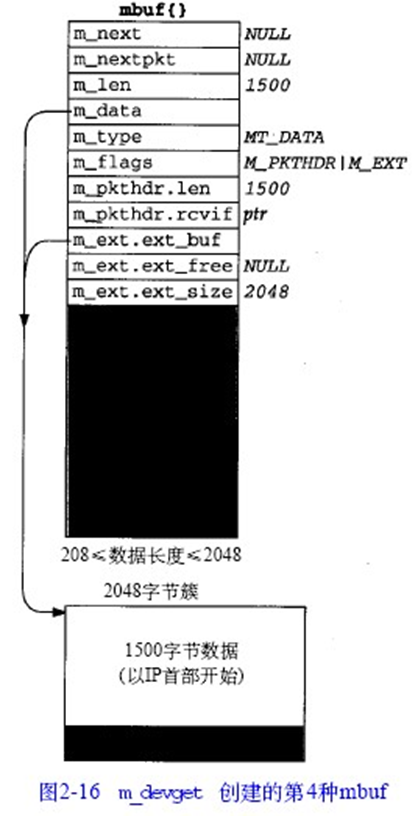
由上图所示,根据mbufflags域,我们可以将mbuf分为4类:
- flags == 0,只包含data,且data最大为108 byte
- flags == M_PKTHDR ,包含8 byte分组头部, data最大为100 byte
- flags == M_EXT,包含2048byte的额外空间,且数据最少为208byte
- flags == M_PKTHDR | M_EXT,在额外空间的基础上多了分组头部,且数据最小长度为208byte
阴影部分为不使用的部分
可以看到,后两类的muf又多了三种域:
m_ext.ext_buf,指向额外空间的起始地址(m_data指向的是缓存的起始)m_ext.ext_free,在Net/3中不使用m_ext.ext_size,额外空间的大小,一般为1024或2048,本书以2048为主mub
简单的mbuf宏和函数
MGET宏
1 |
这里就不做源码上详细解释,自己看应该能懂。只稍微说几个点:
MBUFLOCK宏是用来保证执行mbstat.m_mtypes[type]++的优先级,防止+1时被打断m->data = m->dat是让data指向缓存区域的开始地址- else分支里面是malloc分配失败时的处理
mbstat 是一个用来管理mbuf的全局变量,前面我并没有提到。是因为我觉得这个东西可能不是那么重要,没详细去看😀
m_get函数
1 | struct mbuf* m_get(nowait, type) |
没什么东西,就是MGET宏套了个函数外套。nowait的值为M_WAIT或M_DONTWAIT,取决于在存储器不可用时是否等待。
m_retry函数
1 | struct mbuf* m_retry(i, t) |
这是MGET宏的else分支执行的函数,通过m_relaim()试图腾出一部分空间,然后再次尝试MGET
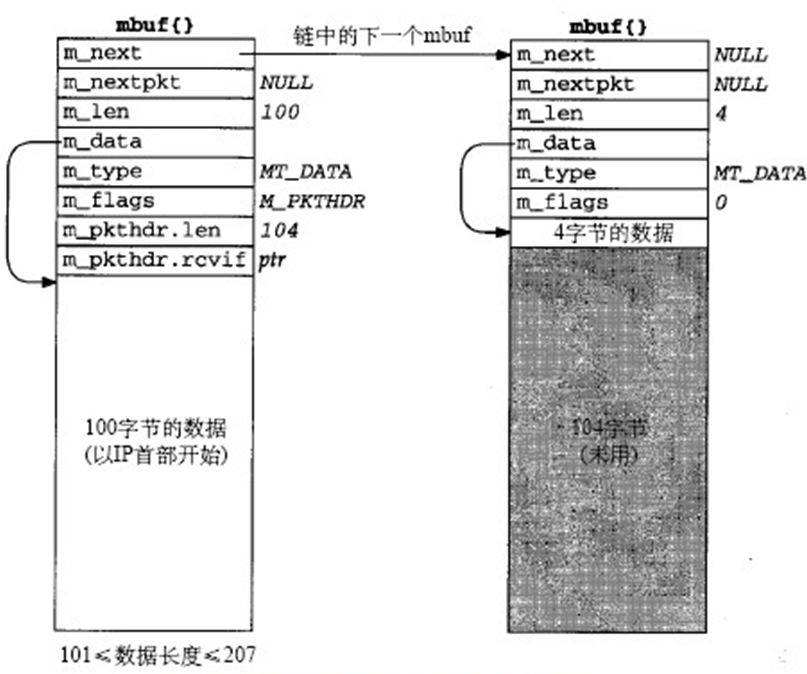
m_devget函数
当接收到以太网帧时,设备驱动程序调用函数m_devget()创建mbuf来接受数据,根据数据长度不同,会形成四种类型的mbuf链表,如下面所示:
mtod和dtom宏
1 |
mtod()宏可以直接理解成mbuf to data,即返回mbuf中的m_data指针,不过额外做了类型转换
dtom()可以理解为data to mbuf,即通过data指针返回指向mbuf的指针
dtom()实际原理也比较简单,MSIZE为128,那么~(MSIZE-1)其实就是0xffffff80,可以明显看到byte的二进制形式位 1000 0000通过清理低位来找到mbuf的起始地址。由于本书全是32位的系统,所以这里我也用的是32位的地址举例。
知道dtom()的原理,很容易就发现其只适用于不含额外扩容的mbuf结构,此时需要m_pullup处理
m_pullup
作用1
当数据报长度小于协议首部大小时,m_pullup会将前N个字节数据重组在第一个mbuf中,试图恢复正常的协议首部。N为传入参数,但是当mbuf链表上数据总长度小于N时,函数将失效,该数据报会被丢弃。
作用2
就是刚刚谈到的dtom()问题,当mbuf中有扩容地址或者说数据在“簇”中存放时,这里m_pullup,将会新建一个mbuf插入链表头,并把簇的前40个byte拷贝近新的mbuf链表头内。
40个字节是因为最大的协议首部为40(20 IP首部+20 TCP首部),这样可以保证在后续传给高层协议处理时,可以正常处理。
下图2-17为处理前,2-18为处理后。另外需要注意到,处理后的m_data指针指向了簇内去除40byte之后的位置,验证了我们之前谈到的m_data指向的是数据的起始,而不是缓存区域的起始。
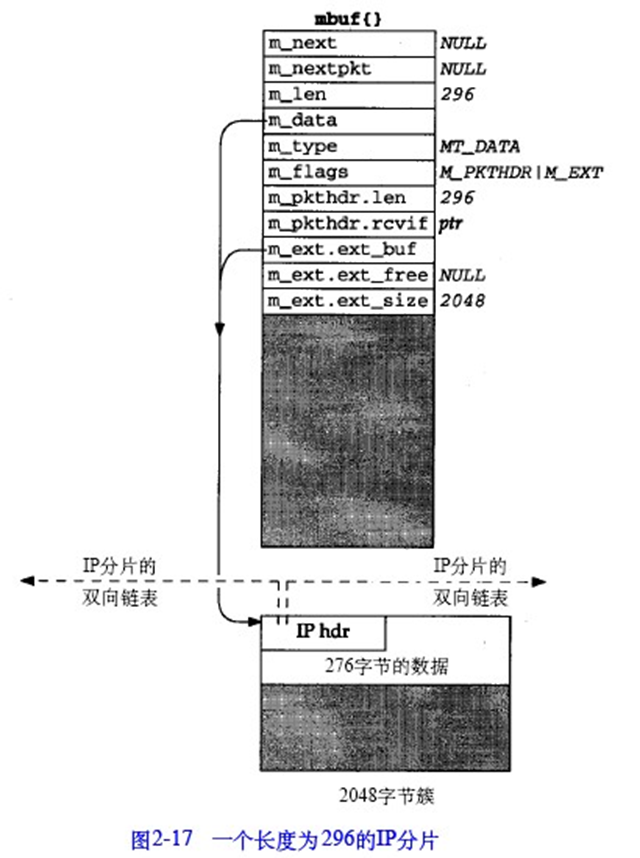
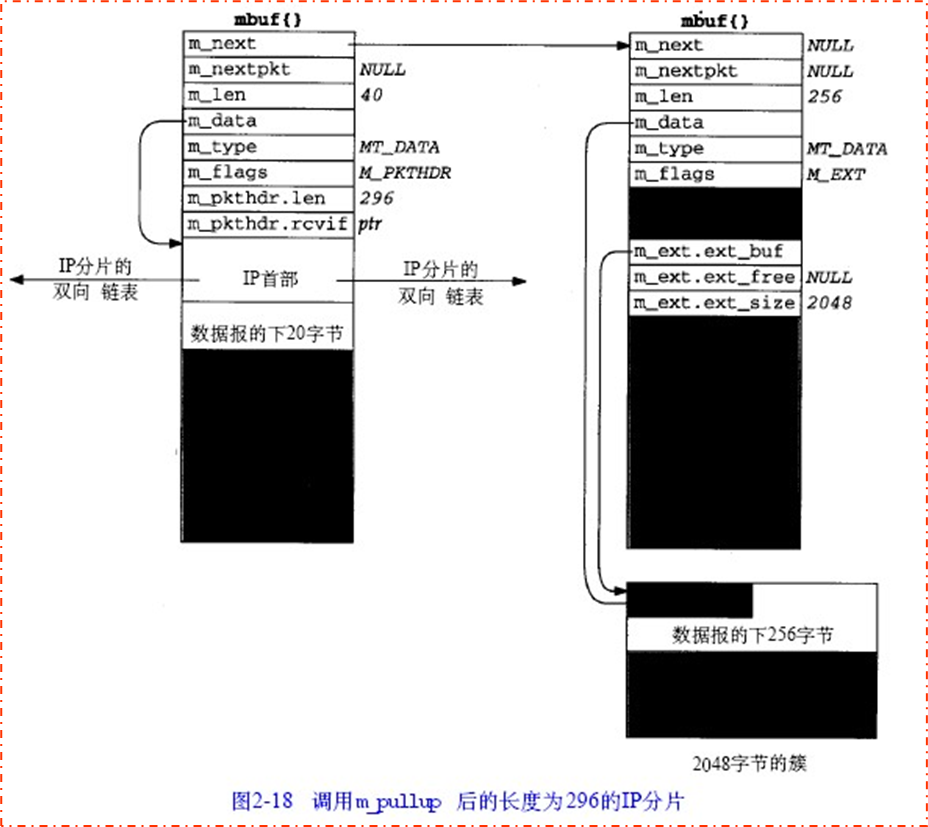
另外需要注意,TCP不使用m_pullup(),而是采取另外不同的技术
联网数据结构小结
个人感觉前面哪些详细分析已经差不多了,这数据结构自己也应该能画出来😝,就放两张图看看就好
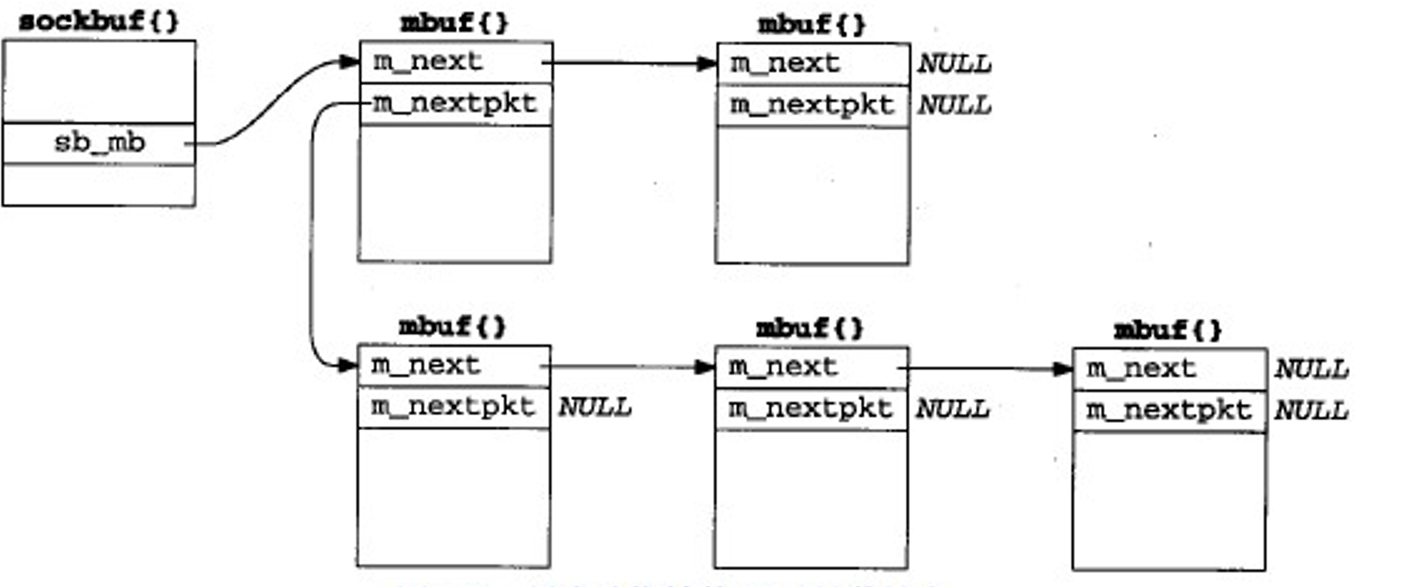
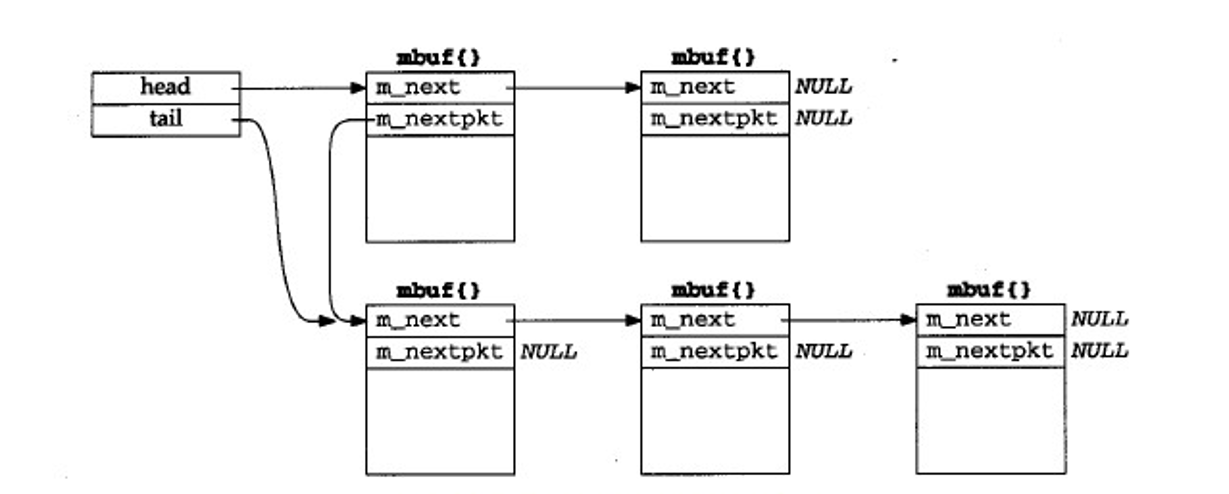
m_copy和簇引用计数
这个part是一个比较有趣的部分,但流程相对来说也更复杂一些
这里我们假设一个例子,一个程序想把共4096byte写入到TCP插口当中,且TCP传输的最大报文大小为1460。那么基本流程如下:
- 先把前2048个byte放入一个簇内,如下图
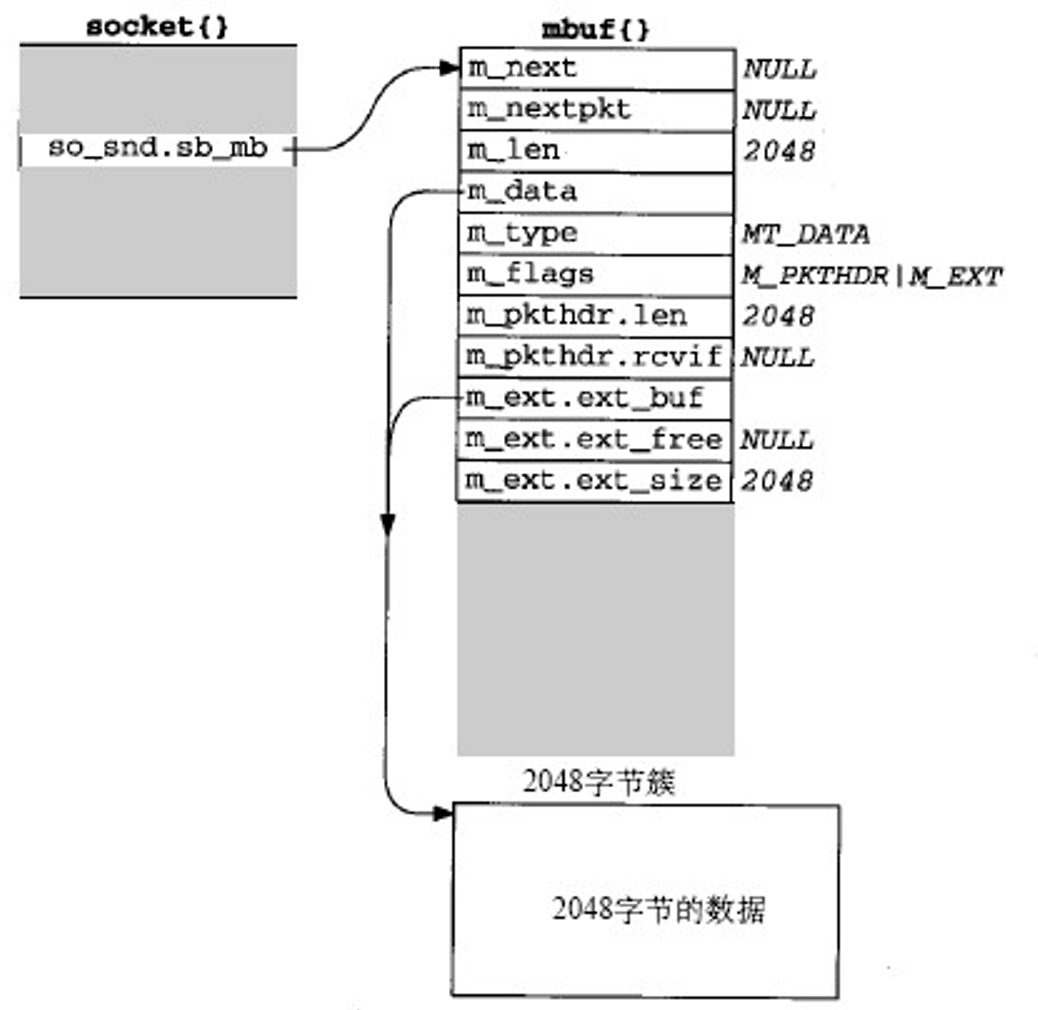
- 新建一个mbuf作为发送出去的mbuf分组首部(左下),再建一个mbuf与步骤1建立的mbuf共享簇(右下),并设置m_len为1460,表示只取前面1460,如图
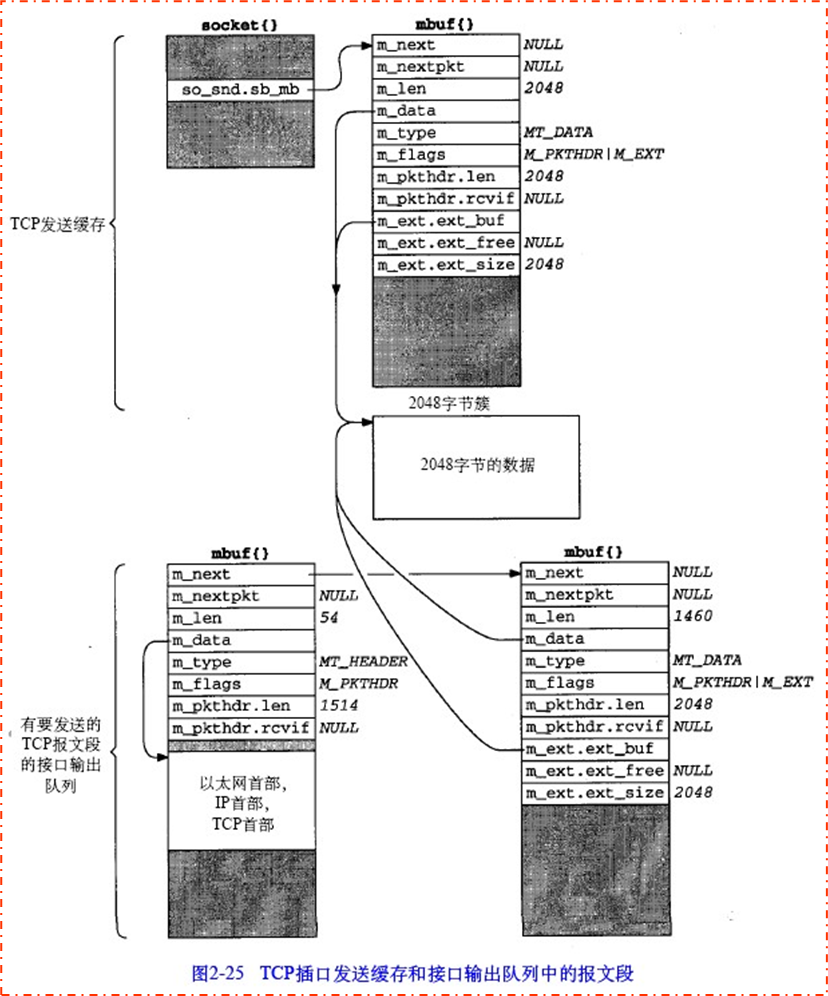
- 将这1460的数据传输出去,然后释放掉mbuf
- 新建一个mbuf(右上)用于存放后2048的byte,同步骤2新建buf链表,不过链表第2个mbuf指向之前未用完的簇后半部分,第三个mbuf指向新的2048
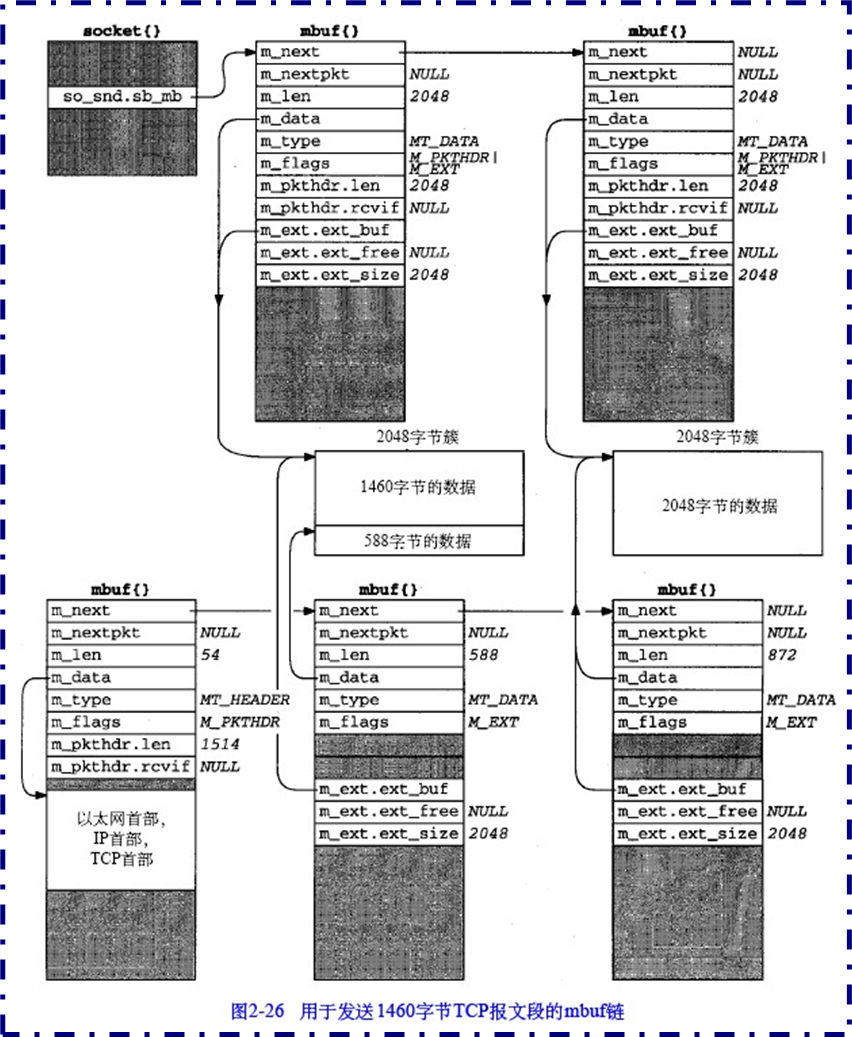
- 不断重复类似上述操作,通过共享簇,将所有数据传输出去
簇引用计数用来表示一个簇同时被几个mbuf指向。每当释放一个mbuf,该mbuf所指向的簇的引用计数-1,当且仅当簇的引用计数为0时,簇可以被释放。这是为了防止在共享簇时,上述操作中的释放mbuf可能会导致释放掉共享的簇而导致数据丢失。
第三章 接口层
ifnet结构
结构ifnet中包含所有接口的通用信息,每个网络设备拥有独立的ifnet结构。ifnet结构有一个列表,包含这个设备的一个或多个协议地址。
1 | struct ifnet { |
这里每个部分都有注释,就不用我解释了吧😭,困死了要,这些b东西能考什么,哥们也背不下来啊
- if_next 将所有ifnet链接为一个单链表
- if_addrlist 指向
ifaddr{}结构列表,每个ifaddr{}与一个协议相对应 - if_name 用于标识接口的类型
- if_unit 用于标识多个相同类型的实例
- if_index在内核中唯一表示这个接口
- if_flags表明接口的操作状态和属性
- if_timer以秒为单位记录时间
- if_pcount和if_bpf,支持BSD分组过滤器
ifaddr结构
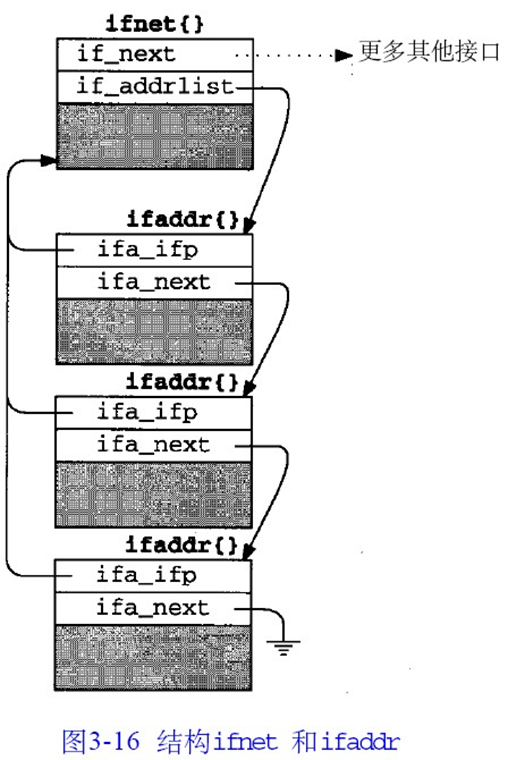
1 | struct ifaddr { |
感觉这两个结构只要搞懂图就差不多了吧😭
sockaddr

看看图差不多得了,这b课真该死啊😅
if_attach
用来完成ifnet结构的初始化和搭建,第三章是真逆天,差不多得了
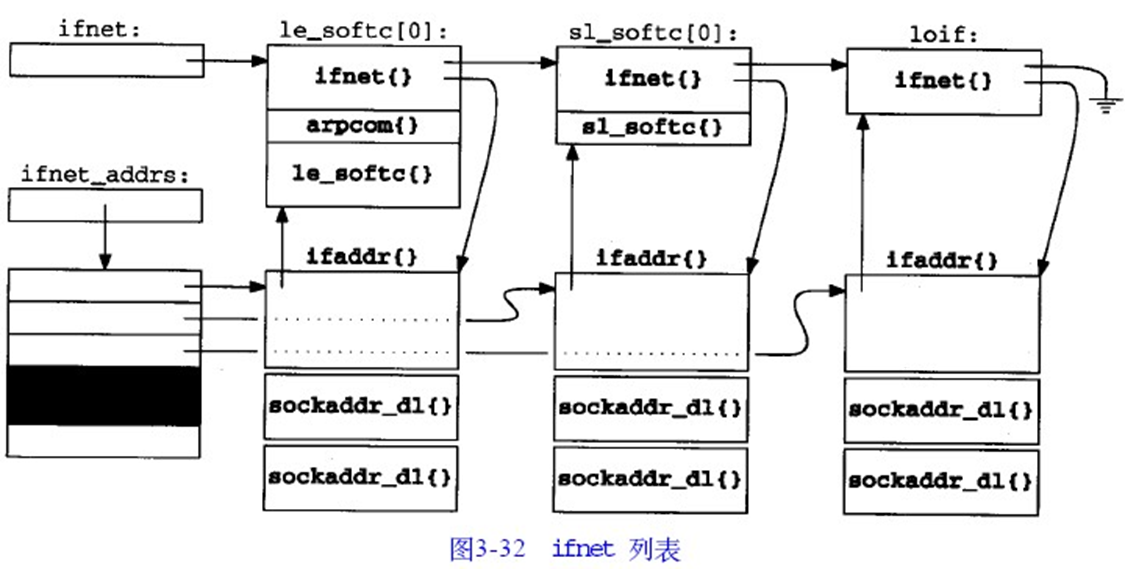
if_attach被调用了三次: 以一个le_softc结构为参数从leattach调用,以一个sl_softc结构为数从slattach调用,以一个通用ifnet结构为参数从loopattach调用。每次调用时,它向ifnet列表中添加一个的ifnet结构,为这个接口创建一个链路层ifaddr结构(包含两个sockaddr_dl结构),并且初始化ifnet_addrs数组中的一项。