前言
最近想研究研究AFL整体内部逻辑源码,面试时也遇到了同样的问题,决定从AFL白皮书开始看看。网上有很多翻译版,但是要不就是没写完,要不就是机翻痕迹太重。决定自己完成这个任务,争取在一周内完成大部分核心源码的分析。又想到之前看网络协议栈和IO_FILE时的噩梦了😭😭😭
本人英语水平有限,如有问题可以文末评论区直接指出。我想做中英双语版也是尽量在一定程度上防止大家被我的蹩脚翻译带偏。
白皮书的原文部分我都会使用markdown的引用语法,另外,全文使用AFL简写替代American fuzzy lop.
AFL白皮书原文:lcamtuf.coredump.cx/afl/technical_details.txt
AFL项目地址:google/AFL: american fuzzy lop - a security-oriented fuzzer (github.com)
本文也部分参考:翻译afl-fuzz白皮书 - 简书 (jianshu.com)
文档介绍
This document provides a quick overview of the guts of American Fuzzy Lop. See README for the general instruction manual; and for a discussion of motivations and design goals behind AFL, see historical_notes.txt.
本文档为AFL的内部结构提供了一个简要的概述。通用说明手册可以直接查阅README]部分,另外,有关AFL背后的设计目标和动机可以参阅hisrotical_notes.txt。
0)Design statement 设计说明
American Fuzzy Lop does its best not to focus on any singular principle of
operation and not be a proof-of-concept for any specific theory. The tool can
be thought of as a collection of hacks that have been tested in practice,
found to be surprisingly effective, and have been implemented in the simplest,
most robust way I could think of at the time
AFL尽力不关注任何单一操作的原理,同时也不是任何特定理论的POC。这个工具可以看作是一个hack工具的集合,这些工具在实际的验证测试场景中非常有效,因此我用了那时我能想到的最简洁最具鲁棒性的方式实现设计了它。
Many of the resulting features are made possible thanks to the availability of
lightweight instrumentation that served as a foundation for the tool, but this
mechanism should be thought of merely as a means to an end. The only true
governing principles are speed, reliability, and ease of use
许多功能能够实现,都是多亏了将轻量化工具的可用性作为该项目的基础,但是这种机制应该仅仅被视作为了实现设计目的的一种手段。本项目真正的唯一的管理原则应是高效性、稳定性和易用性。
1)Coverage measurements 覆盖率测量
The instrumentation injected into compiled programs captures branch (edge)
coverage, along with coarse branch-taken hit counts. The code injected at
branch points is essentially equivalent to:
通过向已编译程序注入检测代码来捕获代码分支(或边缘)的覆盖范围,同时粗略得记录分支命中计数。在分支点注入得代码本质上相当于如下伪代码:
1 | cur_location = <COMPILE_TIME_RANDOM>; |
The cur_location value is generated randomly to simplify the process of
linking complex projects and keep the XOR output distributed uniformly.
- cur_location 的值是随机生成的,以简化链接复杂项目的过程并保持 XOR 输出均匀分布。
The shared_mem[] array is a 64 kB SHM region passed to the instrumented binary
by the caller. Every byte set in the output map can be thought of as a hit for
a particular (branch_src, branch_dst) tuple in the instrumented code.
- Shared_mem[] 数组是一个 64 kB SHM 区域,由调用者传递给已检测的二进制文件。输出映射中的每个字节集都可以被认为是检测代码中特定(branch_src,branch_dst)元组的命中。
The size of the map is chosen so that collisions are sporadic with almost all
of the intended targets, which usually sport between 2k and 10k discoverable
branch points:
选择这个大小的映射,是为了统计几乎所有预测的目标的少量碰撞,而这些目标通常有2K到10K个可见的分支点:
| Branch cnt | Colliding tuples | Example targets |
|---|---|---|
| 1,000 | 0.75% | giflib, lzo |
| 2,000 | 1.5% | zlib, tar, xz |
| 5,000 | 3.5% | libpng, libwebp |
| 10,000 | 7% | libxml |
| 20,000 | 14% | sqlite |
| 50,000 | 30% | - |
At the same time, its size is small enough to allow the map to be analyzed
in a matter of microseconds on the receiving end, and to effortlessly fit
within L2 cache.
同时,由于他的size足够的小,得以允许接收端可以在几微秒的时间内分析映射,并将其放入二级缓存中。
This form of coverage provides considerably more insight into the execution
path of the program than simple block coverage. In particular, it trivially
distinguishes between the following execution traces:
与简单的块覆盖相比,这种形式的覆盖可以更深入地了解程序的执行路径。特别是它可以轻易地区分以下执行流程:
- A -> B -> C -> D -> E (tuples: AB, BC, CD, DE)
- A -> B -> D -> C -> E (tuples: AB, BD, DC, CE)
This aids the discovery of subtle fault conditions in the underlying code,
because security vulnerabilities are more often associated with unexpected
or incorrect state transitions than with merely reaching a new basic block.
这有助于发现底层代码中的微妙故障情况,因为安全漏洞通常与意外或不正确的状态转换相关,而不是仅仅与到达新的基本块相关。
The reason for the shift operation in the last line of the pseudocode shown
earlier in this section is to preserve the directionality of tuples (without
this, A ^ B would be indistinguishable from B ^ A) and to retain the identity
of tight loops (otherwise, A ^ A would be obviously equal to B ^ B).
本节前面所示的伪代码最后一行中进行移位操作的原因是为了保留元组的方向性(没有这个,A ^ B 将与 B ^ A 无法区分)并保留紧密循环的标识(否则, A ^ A 显然等于 B ^ B)。
题外话,我不知道为什么大家都喜欢把这个地方的移位翻译成左移,不论是翻译还是代码层面都不应该出现这种错误吧
The absence of simple saturating arithmetic opcodes on Intel CPUs means that
the hit counters can sometimes wrap around to zero. Since this is a fairly
unlikely and localized event, it’s seen as an acceptable performance trade-off.
英特尔 CPU 上缺乏简单的饱和算术操作码,这意味着命中计数器有时会回滚到零。由于这是一个相当不可能发生的局部事件,因此它被视为可接受的性能权衡。
2)Detecting new behaviors 检测新行为
The fuzzer maintains a global map of tuples seen in previous executions; this
data can be rapidly compared with individual traces and updated in just a couple
of dword- or qword-wide instructions and a simple loop.
模糊器维护先前执行中看到的元组的全局映射;该数据可以快速与单独的迹线进行比较,并只需几个dword或qword的指令和一个简单的循环即可更新。
When a mutated input produces an execution trace containing new tuples, the
corresponding input file is preserved and routed for additional processing
later on (see section #3). Inputs that do not trigger new local-scale state
transitions in the execution trace (i.e., produce no new tuples) are discarded,
even if their overall control flow sequence is unique.
当变异的输入产生包含新元组的程序执行流时,相应的输入文件将被保留并以供稍后进行其他处理(请参阅第 #3 节)。在执行跟踪中,不触发新的局部规模状态转换(即不产生新元组)的输入将被丢弃,即使它们的总体控制流序列是唯一的
This approach allows for a very fine-grained and long-term exploration of
program state while not having to perform any computationally intensive and
fragile global comparisons of complex execution traces, and while avoiding the
scourge of path explosion.
这种方法允许对程序状态进行非常细粒度和长期的探索,而不必对复杂的执行跟踪执行任何计算密集型和脆弱的全局比较,同时避免路径爆炸的危害。
To illustrate the properties of the algorithm, consider that the second trace
shown below would be considered substantially new because of the presence of
new tuples (CA, AE):
为了说明该算法的属性,请考虑由于新元组(CA、AE)的存在,下面显示的第二条轨迹将被视为实质上是新的:
- #1: A -> B -> C -> D -> E
- #2: A -> B -> C -> A -> E
At the same time, with #2 processed, the following pattern will not be seen
as unique, despite having a markedly different overall execution path:
同时,若保存#2路径后,尽管下面的例子整体执行路径明显不同,但将不会被视为一个新的路径:
- #3: A -> B -> C -> A -> B -> C -> A -> B -> C -> D -> E
In addition to detecting new tuples, the fuzzer also considers coarse tuple
hit counts. These are divided into several buckets:
除了检测新元组之外,模糊器还考虑粗元组命中计数。这些被分为几个buckets:
1 | 1, 2, 3, 4-7, 8-15, 16-31, 32-27, 128+ |
To some extent, the number of buckets is an implementation artifact: it allows
an in-place mapping of an 8-bit counter generated by the instrumentation to
an 8-position bitmap relied on by the fuzzer executable to keep track of the
already-seen execution counts for each tuple.
从某种意义上讲,这些buckets的数量是一种执行工具:它允许将生成的 8 位计数器就地映射到fuzzer执行器所依赖的 8 位位图,以跟踪已经看到的数据每个元组的执行计数
Changes within the range of a single bucket are ignored; transition from one
bucket to another is flagged as an interesting change in program control flow,
and is routed to the evolutionary process outlined in the section below.
单个bucket范围内的变化会被忽略掉;然而元组从一个bucket到另一个bucket的转换会被标记为程序控制流中的一个有趣的变化,然后会被保存下来传递至下一轮的演化过程中去。
The hit count behavior provides a way to distinguish between potentially
interesting control flow changes, such as a block of code being executed
twice when it was normally hit only once. At the same time, it is fairly
insensitive to empirically less notable changes, such as a loop going from
47 cycles to 48. The counters also provide some degree of “accidental”
immunity against tuple collisions in dense trace maps.
命中计数行为提供了一种区分潜在的有趣的控制流变换的方法,例如,通常只命中一次的代码块被执行了两次。同时,它对通常经验上不太显着的变化相当不敏感,例如从 47 个周期变为 48 个周期的循环。计数器还提供一定程度的“意外”免疫力,防止密集流映射中的元组碰撞
The execution is policed fairly heavily through memory and execution time
limits; by default, the timeout is set at 5x the initially-calibrated
execution speed, rounded up to 20 ms. The aggressive timeouts are meant to
prevent dramatic fuzzer performance degradation by descending into tarpits
that, say, improve coverage by 1% while being 100x slower; we pragmatically
reject them and hope that the fuzzer will find a less expensive way to reach
the same code. Empirical testing strongly suggests that more generous time
limits are not worth the cost.
通过内存和执行时间对执行过程进行相当严格的限制;默认情况下,超时设置为初始校准执行速度的 5 倍,大约为 20 毫秒。激进的超时限制是为了,防止模糊器性能因陷入某种”陷阱“而急剧下降,例如,将覆盖率提高 1%,同时速度慢 100 倍;我们一定会拒绝这种方法,并希望fuzzer能够找到一种代价更低的方式的方法来达到相同的代码块。同时,实证检验也非常强烈地表明,更宽松的时间限制是不值得的。
3)Evolving the input queue 改进输入队列
Mutated test cases that produced new state transitions within the program are
added to the input queue and used as a starting point for future rounds of
fuzzing. They supplement, but do not automatically replace, existing finds.
在程序中产生新状态转换的变异测试用例被添加到输入队列中,并用作未来几轮模糊测试的起点。它们补充但不会自动取代现有发现地路径。
In contrast to more greedy genetic algorithms, this approach allows the tool
to progressively explore various disjoint and possibly mutually incompatible
features of the underlying data format, as shown in this image:
与更贪婪的遗传算法相比,这种方法允许工具逐步探索各种不相交且可能相互不兼容地特征的底层数据格式,如下图所示:
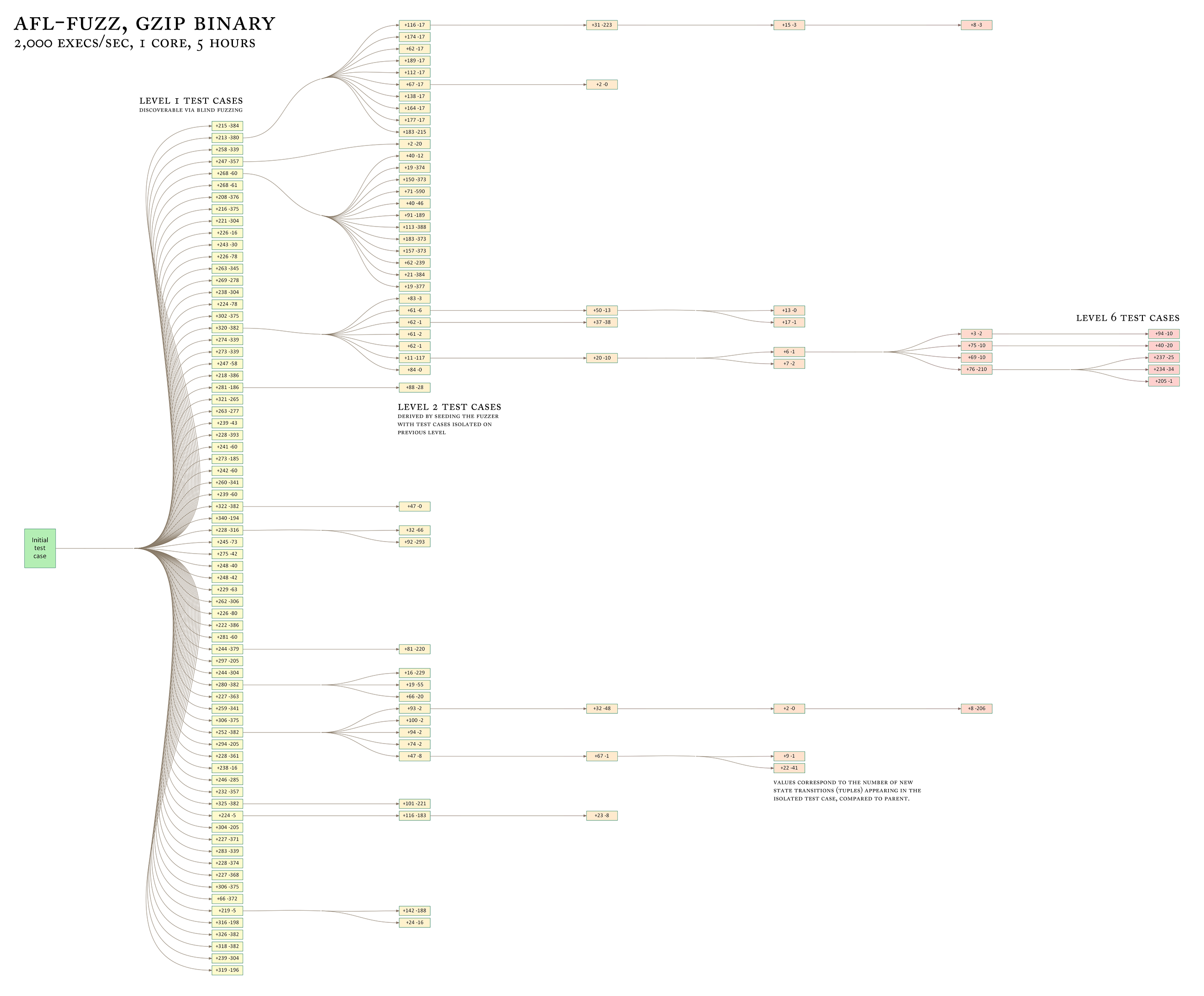
这里讨论该算法结果的几个实际示例:
- http://lcamtuf.blogspot.com/2014/11/pulling-jpegs-out-of-thin-air.html
- http://lcamtuf.blogspot.com/2014/11/pulling-jpegs-out-of-thin-air.html
The synthetic corpus produced by this process is essentially a compact
collection of “hmm, this does something new!” input files, and can be used to
seed any other testing processes down the line (for example, to manually
stress-test resource-intensive desktop apps).
此过程生成的合成语料库本质上是,“嗯,多了一些新的东西!”这样的输入文件的紧凑集合,并且可用于为任何其他测试流程提供种子(例如,手动对资源密集型桌面应用程序进行压力测试)
With this approach, the queue for most targets grows to somewhere between 1k
and 10k entries; approximately 10-30% of this is attributable to the discovery
of new tuples, and the remainder is associated with changes in hit counts
通过这种方法,大多数目标的队列会增长到 1k 到 10k 条目之间;其中大约 10-30% 归因于新元组的发现,其余部分与命中计数的变化有关。
The following table compares the relative ability to discover file syntax and
explore program states when using several different approaches to guided
fuzzing. The instrumented target was GNU patch 2.7.3 compiled with -O3 and
seeded with a dummy text file; the session consisted of a single pass over the
input queue with afl-fuzz:
下表比较了使用几种不同方法进行引导模糊测试时发现文件语法和探索程序状态的相对能力。检测的目标是使用 -O3 编译的 GNU 补丁 2.7.3,并使用虚拟文本文件作为种子;该会话由 afl-fuzz 单次传递的输入队列组成:
| Fuzzer guidance strategy used | Blocks reached | Edges reached | Edge hit cnt var | Highest-coverage test case generated |
|---|---|---|---|---|
| (Initial file) | 156 | 163 | 1.00 | (none) |
| Blind fuzzing S | 182 | 205 | 2.23 | First 2 B of RCS diff |
| Blind fuzzing L | 228 | 265 | 2.23 | First 4 B of -c mode diff |
| Block coverage | 855 | 1,130 | 1.57 | Almost-valid RCS diff |
| Edge coverage | 1,452 | 2,070 | 2.18 | One-chunk -c mode diff |
| AFL model | 1,765 | 2,597 | 4.99 | Four-chunk -c mode diff |
The first entry for blind fuzzing (“S”) corresponds to executing just a single
round of testing; the second set of figures (“L”) shows the fuzzer running in a
loop for a number of execution cycles comparable with that of the instrumented
runs, which required more time to fully process the growing queue.
blind fuzzing(“S”)的第一个条目对应于仅执行一轮测试;第二组图(“L”)显示模糊器在循环中运行的执行周期数与检测运行的运行周期相当,这需要更多时间来完全处理不断增长的队列。
Roughly similar results have been obtained in a separate experiment where the
fuzzer was modified to compile out all the random fuzzing stages and leave just
a series of rudimentary, sequential operations such as walking bit flips.
Because this mode would be incapable of altering the size of the input file,
the sessions were seeded with a valid unified diff:
在另一个实验中获得了大致相似的结果,其中模糊器被修改为编译出所有随机模糊阶段,只留下一系列基本的顺序操作,例如步行位翻转。由于此模式无法更改输入文件的大小,会话使用有效的统一差异设定种子:
| Queue extension strategy used | Blocks reached | Edages reached | Edge hit cnt var | Number of unique crashes found |
|---|---|---|---|---|
| (Initial file) | 624 | 717 | 1.00 | - |
| Blind fuzzing | 1,101 | 1,409 | 1.60 | 0 |
| Block coverage | 1,255 | 1,649 | 1.48 | 0 |
| Edge coverage | 1,259 | 1,734 | 1.72 | 0 |
| AFL model | 1,452 | 2,040 | 3.16 | 1 |
At noted earlier on, some of the prior work on genetic fuzzing relied on
maintaining a single test case and evolving it to maximize coverage. At least
in the tests described above, this “greedy” approach appears to confer no
substantial benefits over blind fuzzing strategies.
如前所述,之前的一些遗传模糊测试工作依赖于维护单个测试用例并对其进行改进以最大化覆盖范围。至少在上述测试中,这种“贪婪”方法似乎并没有比盲目模糊测试策略带来实质性的好处。
4)Culling the corpus 语料库剔除
The progressive state exploration approach outlined above means that some of
the test cases synthesized later on in the game may have edge coverage that
is a strict superset of the coverage provided by their ancestors.
上面概述的渐进状态探索方法意味着,在流程中稍后合成的一些测试用例可能具有边缘覆盖,这是其祖先提供的覆盖的严格超集。
To optimize the fuzzing effort, AFL periodically re-evaluates the queue using a
fast algorithm that selects a smaller subset of test cases that still cover
every tuple seen so far, and whose characteristics make them particularly
favorable to the tool.
为了优化模糊测试工作,AFL 使用快速算法定期重新评估队列,该算法选择较小的测试用例子集,这些测试用例仍然覆盖迄今为止看到的每个元组,并且其特征使它们特别适合该工具。
The algorithm works by assigning every queue entry a score proportional to its
execution latency and file size; and then selecting lowest-scoring candidates
for each tuple.
该算法的工作原理是为每个队列条目分配与其执行延迟和文件大小成比例的分数;然后为每个元组选择得分最低的候选项。
The tuples are then processed sequentially using a simple workflow:
- Find next tuple not yet in the temporary working set,
- Locate the winning queue entry for this tuple,
- Register all tuples present in that entry’s trace in the working set,
- Go to #1 if there are any missing tuples in the set.
然后使用一种简易的流程处理这些元组:
- 找到一个未在临时工作集中的元组
- 找到这个元组的winning队列条目
- 在工作集中注册该条目的所有存在的元组
- 如果在集合里有任何缺少的元组,返回流程1
The generated corpus of “favored” entries is usually 5-10x smaller than the
starting data set. Non-favored entries are not discarded, but they are skipped
with varying probabilities when encountered in the queue:
If there are new, yet-to-be-fuzzed favorites present in the queue, 99% of non-favored entries will be skipped to get to the favored ones.
If there are no new favorites:
If the current non-favored entry was fuzzed before, it will be skipped 95% of the time.
If it hasn’t gone through any fuzzing rounds yet, the odds of skipping drop down to 75%.
Based on empirical testing, this provides a reasonable balance between queue
cycling speed and test case diversity.
生成的”首选”的语料库通常比其实数据集要小 5-10 倍。不受欢迎的条目不会被丢弃,但它们在队列中会以不同概率被跳过:
- 如果队列中存在新的、尚未被fuzz的favorites,则99%的non-favored条目将被跳过,而去访问favored条目
- 如果不存在新的favorites:
- 如果当前non-favored条目之前被fuzz过,则有95%的几率跳过
- 如果当前non-favored条目未被fuzz过,则跳过的几率下降到75%
基于实际测试,这种方式在循环速度和测试用例多样性之间提供了合理的平衡
Slightly more sophisticated but much slower culling can be performed on input
or output corpora with afl-cmin. This tool permanently discards the redundant
entries and produces a smaller corpus suitable for use with afl-fuzz or
external tools.
可以使用 afl-cmin 对输入或输出语料库执行稍微复杂但速度慢得多的剔除。此工具会永久丢弃冗余条目,并生成适合与 afl-fuzz 或外部工具一起使用的较小语料库。
5)Trimming input files 修剪输入文件
File size has a dramatic impact on fuzzing performance, both because large
files make the target binary slower, and because they reduce the likelihood
that a mutation would touch important format control structures, rather than
redundant data blocks. This is discussed in more detail in perf_tips.txt.
文件大小对模糊测试性能有显著影响,这既是因为大文件会使目标二进制文件变慢,也是因为它们降低了突变接触重要格式控制结构的可能性,增大了接触冗余数据块的可能性。在perf_tips.txt中将对此问题做更详细地讨论。
The possibility that the user will provide a low-quality starting corpus aside,
some types of mutations can have the effect of iteratively increasing the size
of the generated files, so it is important to counter this trend.
就算不考虑用户自身提供低质量起始语料库的可能性,某些类型的突变也可能会导致迭代地增加生成文件的大小,因此扭转这种变化趋势非常重要。
Luckily, the instrumentation feedback provides a simple way to automatically
trim down input files while ensuring that the changes made to the files have no
impact on the execution path.
幸运的是,检测反馈提供了一种简单的方法来自动修剪输入文件,同时确保对文件所做的更改不会影响执行路径。
The built-in trimmer in afl-fuzz attempts to sequentially remove blocks of data
with variable length and stepover; any deletion that doesn’t affect the checksum
of the trace map is committed to disk. The trimmer is not designed to be
particularly thorough; instead, it tries to strike a balance between precision
and the number of execve() calls spent on the process, selecting the block size
and stepover to match. The average per-file gains are around 5-20%.
afl-fuzz 中的内置修剪器尝试按顺序删除具有可变长度和跨距的数据块;任何不影响跟踪映射校验和的删除都将提交到磁盘。修剪器的设计不是特别彻底;相反,通过选择匹配数据块大小和跨步大小,它试图在精度和进程execve()调用的数量上取得平衡。每个文件的平均收益为5-20%。
The standalone afl-tmin tool uses a more exhaustive, iterative algorithm, and
also attempts to perform alphabet normalization on the trimmed files. The
operation of afl-tmin is as follows.
独立的 afl-tmin 工具使用更详尽的迭代算法,并且还尝试对修剪后的文件执行字母规范化。afl-tmin的操作如下。
First, the tool automatically selects the operating mode. If the initial input
crashes the target binary, afl-tmin will run in non-instrumented mode, simply
keeping any tweaks that produce a simpler file but still crash the target. If
the target is non-crashing, the tool uses an instrumented mode and keeps only
the tweaks that produce exactly the same execution path.
首先,该工具会自动选择操作模式。如果初始输入使目标二进制文件崩溃,afl-tmin 将以非检测模式运行,只需保留生成更简单文件但仍会使目标崩溃的任何调整。如果目标未崩溃,则该工具使用检测模式,并仅保留生成完全相同执行路径的调整。
The actual minimization algorithm is:
- Attempt to zero large blocks of data with large stepovers. Empirically, this is shown to reduce the number of execs by preempting finer-grained efforts later on.
- Perform a block deletion pass with decreasing block sizes and stepovers, binary-search-style.
- Perform a block deletion pass with decreasing block sizes and stepovers, binary-search-style.
- Perform a block deletion pass with decreasing block sizes and stepovers, binary-search-style.
实际的最小化算法是:
- 尝试将具有大跨距的大数据块归零。从经验上讲,这可以通过抢占以后更细粒度的工作来减少
exec的数量。 - 以递减的块大小和步距执行块删除过程,采用二分搜索方式。
- 通过计算唯一字符并尝试将每个字符批量替换为零值来执行字母规范化。
- 最后,对非零字节执行逐字节归一化。
Instead of zeroing with a 0x00 byte, afl-tmin uses the ASCII digit ‘0’. This
is done because such a modification is much less likely to interfere with
text parsing, so it is more likely to result in successful minimization of
text files.
afl-tmin 使用 ASCII 数字“0”,而不是使用 0x00 字节进行清零。这样做是因为这样的修改不太可能干扰文本解析,因此更有可能成功最小化文本文件。
The algorithm used here is less involved than some other test case
minimization approaches proposed in academic work, but requires far fewer
executions and tends to produce comparable results in most real-world
applications.
这里使用的算法比学术工作中提出的其他一些测试用例最小化方法涉及的程度要少,但需要的执行次数要少得多,并且往往会在大多数实际应用中产生可比较的结果。
6) Fuzzing strategies 模糊测试策略
The feedback provided by the instrumentation makes it easy to understand the
value of various fuzzing strategies and optimize their parameters so that they
work equally well across a wide range of file types. The strategies used by
afl-fuzz are generally format-agnostic and are discussed in more detail here:
http://lcamtuf.blogspot.com/2014/08/binary-fuzzing-strategies-what-works.html
仪器提供的反馈使您可以轻松了解各种模糊测试策略的价值并优化其参数,以便它们在各种文件类型上同样有效。 afl-fuzz 使用的策略通常与格式无关,这里更详细地讨论:
http://lcamtuf.blogspot.com/2014/08/binary-fuzzing-strategies-what-works.html
It is somewhat notable that especially early on, most of the work done by
afl-fuzz is actually highly deterministic, and progresses to random stacked
modifications and test case splicing only at a later stage. The deterministic
strategies include:
- Sequential bit flips with varying lengths and stepovers,
- Sequential addition and subtraction of small integers,
- Sequential addition and subtraction of small integers,
值得注意的是,特别是在早期,afl-fuzz 所做的大部分工作实际上是高度确定性的,并且仅在后期阶段才会进展到随机堆叠修改和测试用例拼接。确定性策略包括:
- 顺序对不同长度和步距的位进行反转
- 顺序对小整数的加减法
- 顺序插入已知的interesting整数(0、1、INT_MAX等)
The purpose of opening with deterministic steps is related to their tendency to
produce compact test cases and small diffs between the non-crashing and crashing
inputs.
以确定性步骤打开的目的与它们生成紧凑测试用例以及非崩溃和崩溃输入之间的小差异的倾向有关。
With deterministic fuzzing out of the way, the non-deterministic steps include
stacked bit flips, insertions, deletions, arithmetics, and splicing of different
test cases.
介绍完确定性模糊测试步骤,非确定性步骤包括堆叠位翻转、插入、删除、算术和不同测试用例的拼接。
The relative yields and execve() costs of all these strategies have been
investigated and are discussed in the aforementioned blog post.
所有这些策略的相对收益率和 execve()的成本都已在上述博客文章中进行了研究和讨论。
For the reasons discussed in historical_notes.txt (chiefly, performance,
simplicity, and reliability), AFL generally does not try to reason about the
relationship between specific mutations and program states; the fuzzing steps
are nominally blind, and are guided only by the evolutionary design of the
input queue.
正如 Historical_notes.txt 中讨论的原因(主要是性能、简单性和可靠性),AFL 通常不会尝试推理特定突变和程序状态之间的关系;模糊测试步骤名义上是盲目的,并且仅受输入队列的进化设计的指导。
That said, there is one (trivial) exception to this rule: when a new queue
entry goes through the initial set of deterministic fuzzing steps, and tweaks to
some regions in the file are observed to have no effect on the checksum of the
execution path, they may be excluded from the remaining phases of
deterministic fuzzing - and the fuzzer may proceed straight to random tweaks.
Especially for verbose, human-readable data formats, this can reduce the number
of execs by 10-40% or so without an appreciable drop in coverage. In extreme
cases, such as normally block-aligned tar archives, the gains can be as high as
90%.
也就是说,此规则有一个(微不足道的)例外:当新队列条目经历初始的一组确定性模糊步骤时,观察到对文件中某些区域的调整对执行路径的校验和没有影响,它们可能会被排除在确定性模糊测试的剩余阶段之外 - 并且模糊器可能会直接进行随机调整。特别是对于冗长的、人类可读的数据格式,这可以将执行数量减少 10-40% 左右,而覆盖率不会明显下降。在极端情况下,例如通常块对齐的 tar 存档,增益可高达 90%。
Because the underlying “effector maps” are local every queue entry and remain
in force only during deterministic stages that do not alter the size or the
general layout of the underlying file, this mechanism appears to work very
reliably and proved to be simple to implement.
由于底层“效应器映射”是每个队列条目的本地信息,并且仅在不改变底层文件的大小或总体布局的确定性阶段保持有效,因此该机制似乎工作非常可靠,并且被证明易于实现。
7)Dictionaries 字典
The feedback provided by the instrumentation makes it easy to automatically
identify syntax tokens in some types of input files, and to detect that certain
combinations of predefined or auto-detected dictionary terms constitute a
valid grammar for the tested parser.
仪器提供的反馈使得自动识别某些类型的输入文件中的语法标记变得容易,并检测预定义或自动检测的字典术语的某些组合是否构成了测试解析器的有效语法。
有关如何在 afl-fuzz 中实现这些功能的讨论可以在此处找到:
http://lcamtuf.blogspot.com/2015/01/afl-fuzz-making-up-grammar-with.html
In essence, when basic, typically easily-obtained syntax tokens are combined
together in a purely random manner, the instrumentation and the evolutionary
design of the queue together provide a feedback mechanism to differentiate
between meaningless mutations and ones that trigger new behaviors in the
instrumented code - and to incrementally build more complex syntax on top of
this discovery.
本质上,当基本的、通常容易获得的语法标记以纯粹随机的方式组合在一起时,队列的检测和进化设计一起提供了一种反馈机制,以区分无意义的突变和在检测代码中触发新行为的突变- 并在此发现的基础上逐步构建更复杂的语法。
The dictionaries have been shown to enable the fuzzer to rapidly reconstruct
the grammar of highly verbose and complex languages such as JavaScript, SQL,
or XML; several examples of generated SQL statements are given in the blog
post mentioned above.
事实证明,字典可以使模糊器快速重建高度冗长和复杂的语言(例如 JavaScript、SQL 或 XML)的语法;上面提到的博客文章中给出了生成 SQL 语句的几个示例。
Interestingly, the AFL instrumentation also allows the fuzzer to automatically
isolate syntax tokens already present in an input file. It can do so by looking
for run of bytes that, when flipped, produce a consistent change to the
program’s execution path; this is suggestive of an underlying atomic comparison
to a predefined value baked into the code. The fuzzer relies on this signal
to build compact “auto dictionaries” that are then used in conjunction with
other fuzzing strategies.
有趣的是,AFL 检测还允许模糊器自动隔离输入文件中已存在的语法标记。它可以通过查找字节运行来实现这一点,这些字节在翻转时会对程序的执行路径产生一致的更改;这表明代码中预定义值存在底层原子化的比较。模糊器依靠这个信号来构建紧凑的“自动字典”,然后与其他模糊策略结合使用。
8)De-duping crashes 重复数据删除崩溃
De-duplication of crashes is one of the more important problems for any
competent fuzzing tool. Many of the naive approaches run into problems; in
particular, looking just at the faulting address may lead to completely
unrelated issues being clustered together if the fault happens in a common
library function (say, strcmp, strcpy); while checksumming call stack
backtraces can lead to extreme crash count inflation if the fault can be
reached through a number of different, possibly recursive code paths.
对于任何有能力的模糊测试工具来说,如何删除重复数据是最重要的问题之一。许多简单的方法都会遇到问题。尤其是,如果故障发生在公共库函数(例如 strcmp、strcpy)中,则仅查看故障地址可能会导致完全不相关的问题聚集在一起;如果可以通过许多不同的、可能是递归的代码路径到达故障,则对调用堆栈回溯进行校验和可能会导致大量异常的崩溃计数。
The solution implemented in afl-fuzz considers a crash unique if any of two
conditions are met:
- The crash trace includes a tuple not seen in any of the previous crashes,
- The crash trace is missing a tuple that was always present in earlier faults.
如果满足下列两个条件的任意一种,afl-fuzz中实现的解决方案就会将其认定为一种crash
- 若这个crash包含一个从未在其他crash中出现过的元组
- 若这个crash不包含一个总是在其他crash中出现的元组
The approach is vulnerable to some path count inflation early on, but exhibits
a very strong self-limiting effect, similar to the execution path analysis
logic that is the cornerstone of afl-fuzz.
该方法早期容易受到路径计数膨胀的影响,但其表现出非常强的自我限制效应,同样体现在 afl-fuzz 基石的执行路径分析逻辑。
9)Investigating crashes 调查崩溃
The exploitability of many types of crashes can be ambiguous; afl-fuzz tries
to address this by providing a crash exploration mode where a known-faulting
test case is fuzzed in a manner very similar to the normal operation of the
fuzzer, but with a constraint that causes any non-crashing mutations to be
thrown away.
许多类型的崩溃的可利用性可能是不明确的; afl-fuzz 试图通过提供崩溃探索模式来解决这个问题,其中已知故障的测试用例以与模糊器正常操作非常相似的方式进行模糊测试,但有一个约束,导致任何非崩溃的突变都被丢弃。
有关此方法价值的详细讨论可以在此处找到
The method uses instrumentation feedback to explore the state of the crashing
program to get past the ambiguous faulting condition and then isolate the
newly-found inputs for human review.
该方法使用仪器反馈来探索崩溃程序的状态,以克服模糊的故障条件,然后隔离新发现的输入以供人工审查。
On the subject of crashes, it is worth noting that in contrast to normal
queue entries, crashing inputs are not trimmed; they are kept exactly as
discovered to make it easier to compare them to the parent, non-crashing entry
in the queue. That said, afl-tmin can be used to shrink them at will.
关于崩溃问题,值得注意的是,与正常队列条目相比,崩溃输入不会被修剪;它们完全按照发现的方式保存,以便更容易将它们与队列中的父非崩溃条目进行比较。也就是说,afl-tmin 可以用来随意缩小它们。
10)The fork server
To improve performance, afl-fuzz uses a “fork server”, where the fuzzed process
goes through execve(), linking, and libc initialization only once, and is then
cloned from a stopped process image by leveraging copy-on-write. The
implementation is described in more detail here:
为了提高性能,afl-fuzz 使用“fork server”,其中模糊化进程仅执行一次 execve()、链接和 libc 初始化,然后通过利用copy-on-write从停止的进程映像进行克隆。这里更详细地描述了该实现:
The fork server is an integral aspect of the injected instrumentation and
simply stops at the first instrumented function to await commands from
afl-fuzz.
fork server是注入检测的一个组成部分,它只是在第一个检测函数处停止以等待来自 afl-fuzz 的命令。
With fast targets, the fork server can offer considerable performance gains,
usually between 1.5x and 2x. It is also possible to:
- Use the fork server in manual (“deferred”) mode, skipping over larger, user-selected chunks of initialization code. It requires very modest code changes to the targeted program, and With some targets, can produce 10x+ performance gains.
- Enable “persistent” mode, where a single process is used to try out multiple inputs, greatly limiting the overhead of repetitive fork() calls. This generally requires some code changes to the targeted program, but can improve the performance of fast targets by a factor of 5 or more - approximating the benefits of in-process fuzzing jobs while still maintaining very robust isolation between the fuzzer process and the targeted binary.
对于fast目标,fork server可以提供相当大的性能提升,通常在1.5倍到2倍之间。还可以:
- 在手动的(“deferred”)模式下使用fork server,跳过较大的、用户选择的初始化代码块。它需要对目标程序进行恰到好处的代码更改,并且对于某些目标,可以产生10倍以上的性能提升
- 启用“persistent”模式,其中单个进程用于尝试多个输入,极大的限制了重复
fork()调用的开销。这通常需要对目标程序进行一些代码更改,大可以将fast目标的性能提高5倍或者更多 - 近似于进程内模糊测试作业的好处,同时仍然保持fuzzer进程和目标二进制文件之间巨大的隔离。
其他部分
剩下3章感觉不是很重要,可以自己去看看。之后有空再补上这部分吧