Dive in to sea of nodes!
前置
V8环境构建
可见我博客之前部分的内容V8研究环境搭建,不再过多阐述。
Turbolizer
Turbolizer是一个图形化的工具,可以用辅助调试Turbofan的sea of nodes
1 | # 安装 |
当使用d8运行JS文件时,可以使用参数--trace-turbo参数,会在当前目录.cfg和.json文件,导入web工具便可以正常使用了。
Overview
首先,简要理解一下V8是如何在高层次上工作的
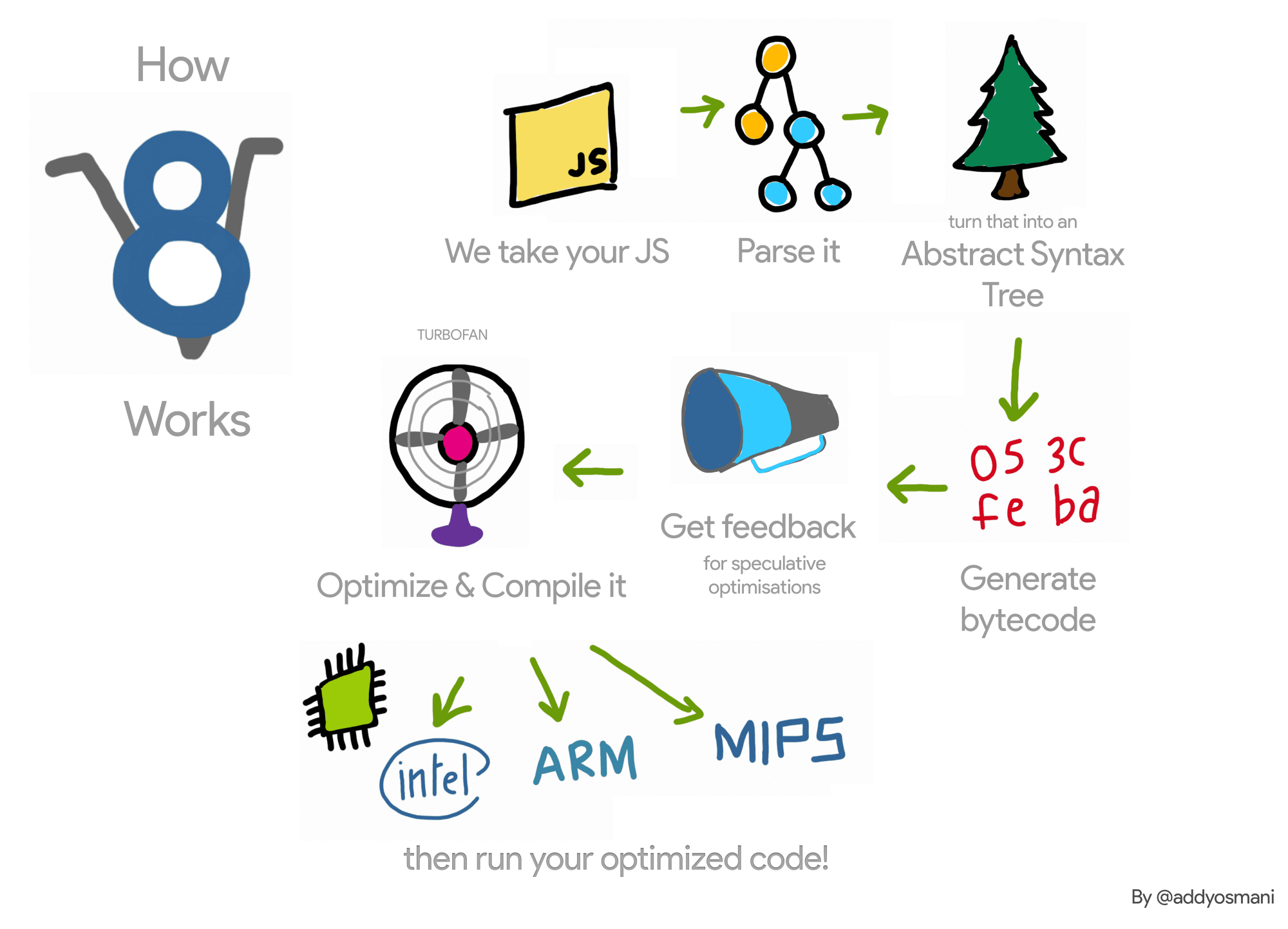
每当 Chrome 或 Node.js 必须执行某些 JavaScript 时,它会将源代码传递给 V8。V8 获取该 JavaScript 源代码并将其提供给所谓的Parser,该Parser会为源代码创建创建AST(Abstract Syntax Tree).之后,AST被传递给Ignition Interpreter,在那里被转换为字节码序列。然后Ignition 会执行此字节码序列,并在执行的过程中,Ignition会收集有关某些操作输入的分析信息或反馈,以优化后续执行的字节码。
Compilation pipeline
以如下代码举例
1 | let f = (o) => { |
使用参数--trace-opt可以跟踪优化,并且在输出中我们也能够看到f函数被TurboFan优化,如下图所示。

v8首先会生成ignition bytecode,如果这个函数会被执行很多次,TurboFan将会生成一些优化的代码。Ignition会收集类型信息,帮助Turbon进行代码的推测优化,推测意味着优化后的代码的运行是由假设前提决定的。
举个例子,有如下代码,存在两个类player和wall,以及一个函数move用来对对象做操作
1 | class Player{} |
如果我们用 move始终移动 Player 类型的对象,那么 Turbofan 生成的优化代码将假设期望接收 Player 对象,并且在这种情况下代码运行速度会非常快。
但是,如果 10 分钟后,由于某种原因,代码移动了wall而不是player,这将打破TurboFan最初做出的假设。其生成的优化代码非常快,但也只能处理 Player 对象。因此,它需要被销毁,并生成一些ignition bytecode。这称为deoptimization,它需要消耗巨大的性能成本。如果我们继续移动 Wall 和 Player,TurboFan 将考虑到这一点并相应地再次优化代码。
使用参数--trace-opt和--trace-deopt可以用来观察优化的过程
1 | class Player{} |
Sea of Nodes
Just a few words on sea of nodes. TurboFan works on a program representation called a
sea of nodes. Nodes can represent arithmetic operations, load, stores, calls, constants etc. There are three types of edges that we describe one by one below.
简单来说,TurboFan工作在称为sea of nodes的程序表示的基础上。Nodes可以用来代表算术运算、负载、存储、调用、常量等。我们将在下文逐一介绍三种类型的edges.
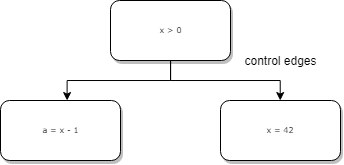
Control edges
Control edges与“控制流图”中的边类型相同,它们用于分支和循环。
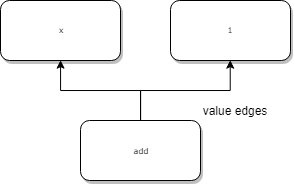
Value edges
Value edges是“数据流图”中的边,拥有值依赖性
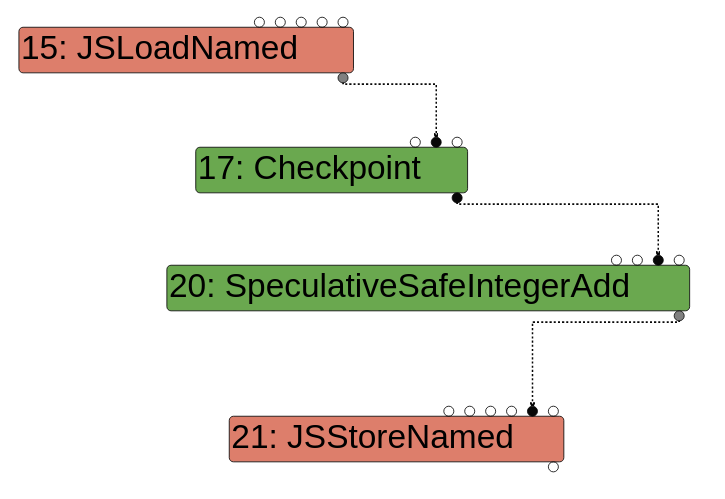
Effect edges
Effect edges主要对于读写这样的操作进行排序。
例如obj[x] = obj[x] + 1这样的情况下,赋值发生在读取obj[x]之后,也就是说,读和写之间存在Effect edges,因此需要在读、加、写等操作之间需要使用Effect edges进行链接,最终形成 load -> add -> store这样的effect chain如下图:
optimization phases
TurboFan的优化过程已经存在了许多漏洞,如incorrect typing of Math.expm1, [incorrect typing of String.(last)IndexOf](https://bugs.chromium.org/p/chromium/issues/detail?id=762874&can=2&q=762874&colspec=ID Pri M Stars ReleaseBlock Component Status Owner Summary OS Modified).
为了理解优化过程,阅读相关代码是最直接的方式,几个关键位置如下:
src/builtin
所有内置函数(如
Array#concat)都实现在这里src/runtime
实现所有运行时函数(如
%DebugPrint)的位置src/interpreter/interpreter-generator.cc
实现所有字节码处理程序的位置
src/compiler
TurboFan的主要仓库!
src/compiler/pipeline.cc
构建图表、运行每个阶段和优化传递等的处理代码
src/compiler/opcodes.h
定义 TurboFan 使用的所有操作码的宏
src/compiler/typer.cc
通过 Typer reducer 实现打字
src/compiler/operation-typer.cc
实现 Typer reducer 使用的其他一些类型化
src/compiler/simplified-lowering.cc
实现简化的降低,其中将进行一些 CheckBounds 消除
优化流程
以如下代码为例:
1 | function opt_me() { |
我们可以使用多次运行或是使用%OptimizeFuctionOnNextCall进行强制代码优化。使用--trace-turbo参数生成用于turbolizer 的文件
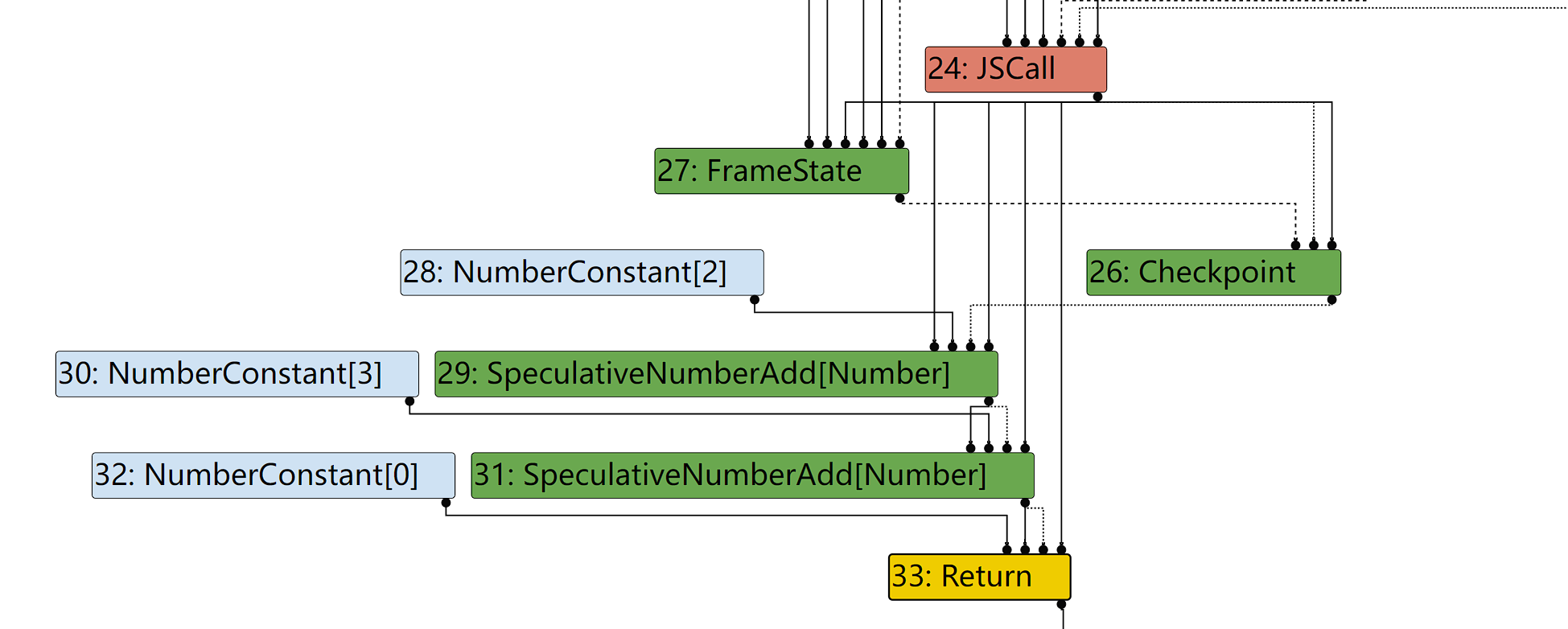
Graph builder phase
可以直观的看到NumberConstant以及SpeculativeNumberAdd 是根据函数中的x+2,x+3部分得到的。
Typer phase
在图像创建后,就会进入优化阶段。优化阶段前期的一种优化方式为TyperPhase,由OptimizeGraph调用,代码如下:
1 | // pipeline.cc |
1 | // pipeline.cc |
当Typer开始运行,他会遍历图中所有的node,并尝试减少一些node
1 | // typer.cc |
1 | // typer.cc |
每当TyperPhase遍历至一个JSCall的node,便会调用JSCallTyper进行处理。如果我们查看JSCallTyper的代码,我们会发现每当被调用函数是一个内置函数时,它都会将一个Type与其关联起来。例如,对于内置函数 MathRandom,它清楚预测返回类型应当时Type::PlainNumber.
1 | Type Typer::Visitor::TypeNumberConstant(Node* node) { |
对于节点NumberConstant来说就更简洁了,只需要读取TypeNumberConstant.在大多数情况下,这个类型将会是Range.若是SpeculativeNumberAdd的情况,可以查看OperationTyper.
1 |
|
根据这里的宏定义,他们最终被OperationTyper::NumberAdd(Type lhs, Type rhs)处理。为了获取右输入节点和左输入节点的类型,我们在它们上都调用 SpeculativeToNumber。为了简单起见,任何类型的 Type::Number 都将保持相同的类型(PlainNumber 本身是 Number,它将保持 PlainNumber类型)。Range(n,n) 类型也将变成一个 Number,以便我们最终在两个 Number 上调用 NumberAdd。NumberAdd 主要检查一些极端情况,例如,两种类型中的一种是否为 MinusZero。在大多数情况下,该函数将仅返回 PlainNumber 类型。
因此类型的变化流程:JSCall(MathRandom)变为PlainNumber -> NumberConstant[n]在n != NaN & n != -0时变为Range(n, n) -> Range(n, n)的类型变为PlainNumber -> SpeculativeNumberAdd(PlainNumber, PlainNumber)的类型变为PlainNumber
未完待续…
临时有更重要的工作任务,后续在补写